
Cellular IoT Development
Cellular IoT is what some might call the new kid on the block – in some ways it is; on the other hand it is based on an existing infrastructure – cellular networks, which is used on every mobile phone in the world. Cellular IoT is rapidly developing, and will eventually become the driving component of many businesses. If you’d like to get a better overview of cellular IoT, I’d recommend this article –https://www.iotforall.com/what-is-cellular-iot.
In this article, we’ll take a quick look at developing cellular IoT devices, and some of the major things to keep in mind during development.
To begin with, it is critical that you have a solid understanding of the hardware before diving into the firmware. As with any hardware/firmware engineering project, picking components is one of the first steps.
To keep things fairly simple, let’s consider an IoT device, which uses a cellular modem for communications, has one or more sensors, and is battery powered. The hardware setup for this IoT device could look like this:
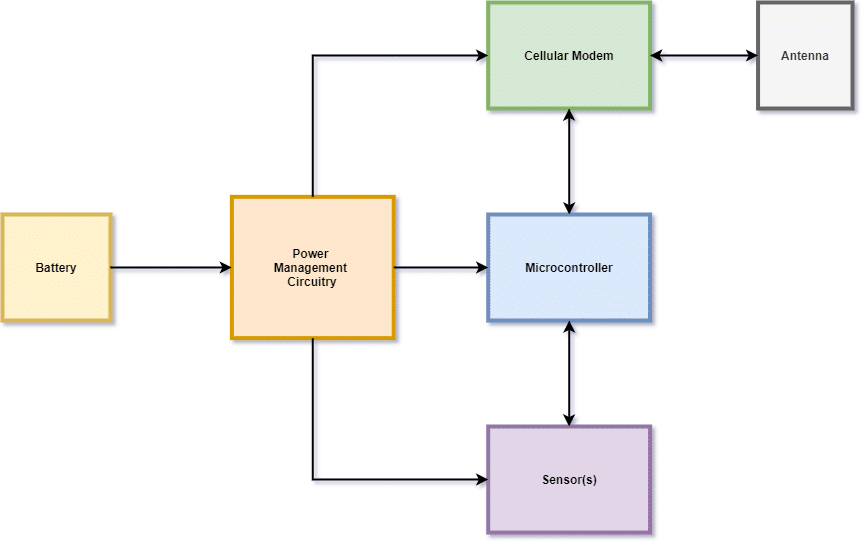
Here you have the core components:
- A battery
- A microcontroller (typically low power)
- A cellular modem (and antenna)
- One or more sensors, depending on your application/use case
- Power circuitry
So far, I find the cellular modem to be the most complex component – mainly because it’s a self contained system which we have virtually no control over. To develop the firmware for a cellular IoT device, here are a few key points to keep in mind:
Power Management
Most cellular modems have a defined power up sequence, and you need to keep this in mind when writing initialization code. Refer to the datasheet of your chosen modem to get the exact details. Moreover, power management needs to be a key consideration in your design especially since the cellular modem is typically the most power-hungry component. In your hardware design, be sure to accommodate peak current of up to 2 Amps, to be on a safe side.
Depending on your application requirements, your IoT device may be required to be powered on at all times, but then only send data at specified intervals. One possible power management scenario could be:
- The microcontroller is always powered on, but is in low power mode – check your microcontroller documentation/settings for how to configure these low power modes.
- The sensors are usually powered off, until they are ready to be used. This is determined and controlled by the application.
- The cellular modem is usually powered off until data is ready to be transmitted or received.
In this scenario, your hardware design needs to accommodate a seamless power on/off mechanism for each of the components. Doing so goes a long way in minimizing power consumption – a key consideration in battery powered IoT devices.
Looking specifically at the modem, you can apply one or more of the following power management options:
- Use AT commands to put the modem in some kind of low power mode, if supported.
- Use Power Saving Mode (PSM) or eDRX (Extended Discontinuous Reception) functionality provided by the modem, if supported. Tread carefully here, as these features may depend on cellular operators may cause more problems than they solve if not properly configured.
- Completely cut off power to the modem when it is not needed. This is achieved typically though a combination of hardware and firmware. What’s extremely important here is to ensure that you gracefully shut down the modem (typically via AT commands) before completely cutting off power. Abrupt shutdowns of the modem tends to cause a lot of problems, such as potentially corrupting the modem firmware, or being denied from connecting to a cellular network because it did not “gracefully” disconnect, or some other weird reasons. Either way, the point here is to ensure that the modem shutdown sequence is graceful. The documentation will often describe how to do a shutdown sequence properly.
Core Modem (and IoT device) Functionality
Functionally speaking, cellular modems in IoT device serve one primary purpose: sending and receiving data remotely. To do this, the application firmware typically needs to implement, as a bare minimum, the following:
- Initialization – turn on the modem and gracefully shut it down, as well as initializing the AT/UART interface,
- Network functionality – setting up and tearing down a cellular network connection,
- Establishing a PDP context – which in (oversimplified) terms, is essentially connecting to the internet and receiving an IP address,
- Server functionality – setting up and tearing down a connection to a remote host/server. This is where the IoT device “dumps” data to,
- Data transmission/reception – the actual sending and receiving of data. How this is done depends on what protocol is being used (raw TCP, HTTP, MQTT, etc).
Therefore, to implement the above-mentioned features in firmware, one way to go about it is to develop the following modules:
- An AT interface – built on top your UART driver, this will be responsible for sending AT commands and receiving the raw responses,
- An AT response parser – all AT commands return responses in various formats. You need to develop a parser to be able to extract the necessary information,
Using these two modules as a base, you could then implement “higher level” modules for:
- “Device level” functionality – for stuff like reading modem information and configuring it.
- “Network level” functionality – for setup network connectivity parameters, reading network connectivity data, setting up/tearing down network connection, etc. This module could also be used to implement setup and teardown of PDP context.
- “Server level” functionality – for setup and teardown of remote server connection, TLS connection, sending/receiving device data, etc.
On a final note, you also need to consider to implement the ability to perform an upgrade of the modem firmware. This is extremely important, as this firmware essentially dictates how the modem works and communicates with the cellular network. For certain certifications, this is even a major requirement.
Conclusion
Developing cellular IoT devices is a challenging endeavour, and there are a lot of key considerations to be kept in mind when designing such a device. These considerations include, but are not limited to:
- Modem selection – you want to pick modems that support the protocols and network technologies (LTE CAT-M1, NB-IoT, etc) needed for your product.
- Efficient power management (which needs to be implemented both in hardware and software).
- Ability to upgrade modem firmware
- Developing modem “drivers”, and your final application. Write your modem drivers and abstract as much as possible, which will make it easy to switch modems when/if necessary.








Recent Comments